Introduction
- My analysis starts with the implementation of the Elliptical-Weighted-Average (EWA) algorithm within the PyResample open source Python implementation (with some Cython modules for speed)
- The PyResample implementation is based upon the implementation within the MODIS-Swath-to-Grid-Toolbox(MS2GT) developed and distributed by NSIDC. See: https://nsidc.org/data/user-resources/help-center/what-modis-swath-grid-toolbox-ms2gt-and-what-can-it-do
- MS2GT is based upon an algorithm developed by Green & Heckbert, IEEE, June 1986
"Creating Raster Omnimax Images from Multiple Perspective Views Using the Elliptical Weighted Average Filter".
https://ieeexplore.ieee.org/document/4056910 - None of this provides much clarity in defining the image characteristics and performance of the algorithm.
- See also, as an introduction, two wiki pages I developed a few years back: ESDIS-SDPS Earth-Data Projection Introduction and Forward-Projection and Reverse-Projection Algorithms
The EWA Algorithm for swath data projection is a highly efficient and well-established approach for projecting Earth-Observational swath data to a “regular" grid. It likely also has some possible “off-label” applications to projecting geographically gridded data and general data regridding - without reprojection (shifting grid alignment and changing resolution). Another possible application would be to general reprojection of projected data grids.
History and Relevancy
- EWA was developed at NSIDC for MODIS swath data handling, circa 1990’s. Originally developed (and still available) as part of MODIS Swath-to-Grid Toolbox (MS2GT)
- It is designed and capable of handling swath data with multiple rows per scan, containing data points “across-track” per scan and with rows being “along-track" to the satellite or aircraft path. Such data can exhibit the so-called “bow-tie” effect where the sample-spot (data cell) reflects an increasing area away from the nadir observation directly below the satellite. This includes side to side angular stretching, as well as some forwards and backwards stretching across multiple scan-rows of data. These angular perspectives create an elliptical stretch of the sample-spot away from the center of the scan.
- The original IEEE article includes a diagram showing the elliptical source cell to target cell mapping (shown left to right below). This corresponds to the stretching of the data acquisition sample spot when off-nadir to the satellite instrument.

Comparison of swath projection and grid reprojection
- Note that the elliptical perspective of the EWA algorithm for swath data is quite similar to the Tissot Indicatrix ellipse of earth-data-to-flat-map projections – which shows the east-west and north-south angular distortion of a projection. There will be more discussion on this later in “off-label” applications of the EWA algorithm. [Application of EWA for grids would not involve multiple rows-per-scan of swath data acquisition, rather referring to just one row of projected data per step through the rows (rows-per-scan = 1)].
- In fact, even within the EWA algorithm, there is the elliptical area of the "sample-spot", and there is a Tissot ellipse of projection stretch (distortion) of the sample spot to a flat-earth grid. The algorithm does not particularly focus on these two sources of elliptical coverage separately, but simply computes an ellipse of coverage from the source data to the target grid.
- This article provides a good introduction to Tissot's Indicatrix: https://www.esri.com/arcgis-blog/products/product/mapping/tissots-indicatrix-helps-illustrate-map-projection-distortion/
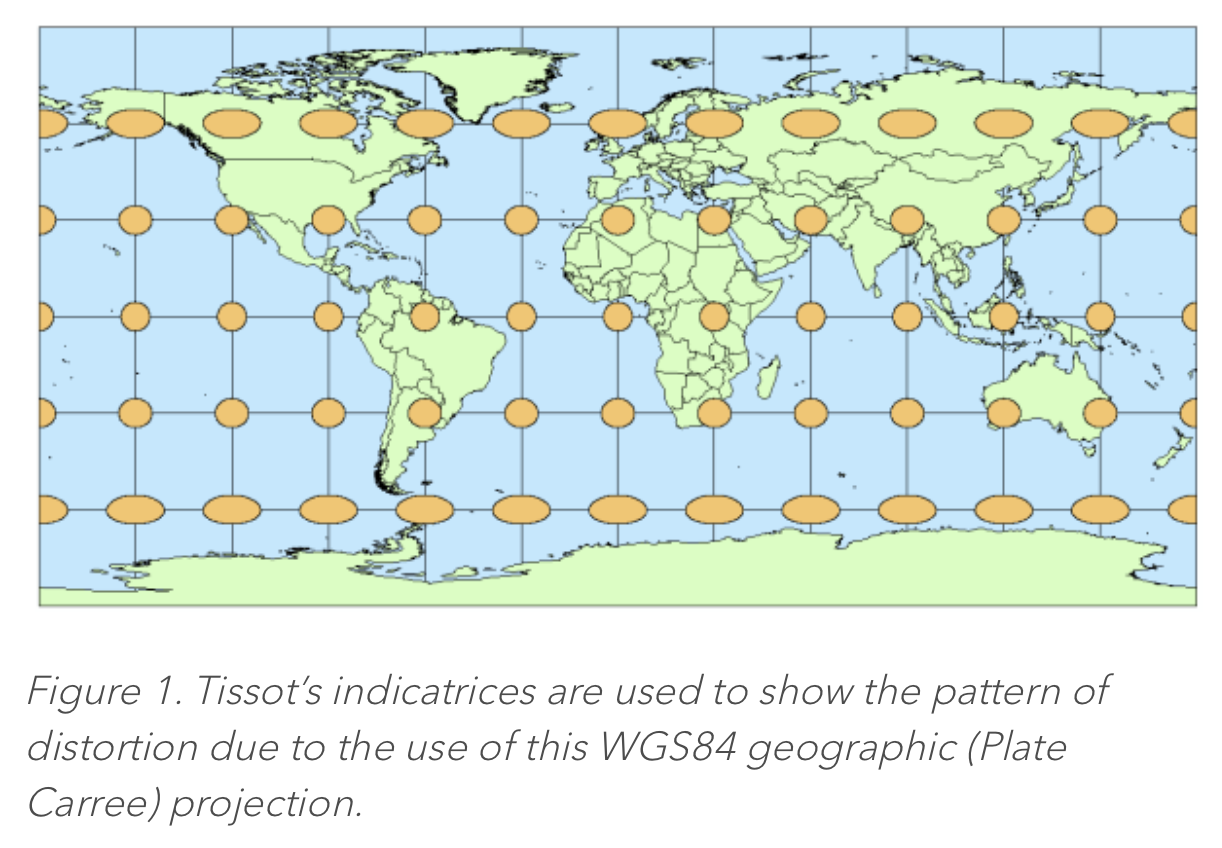
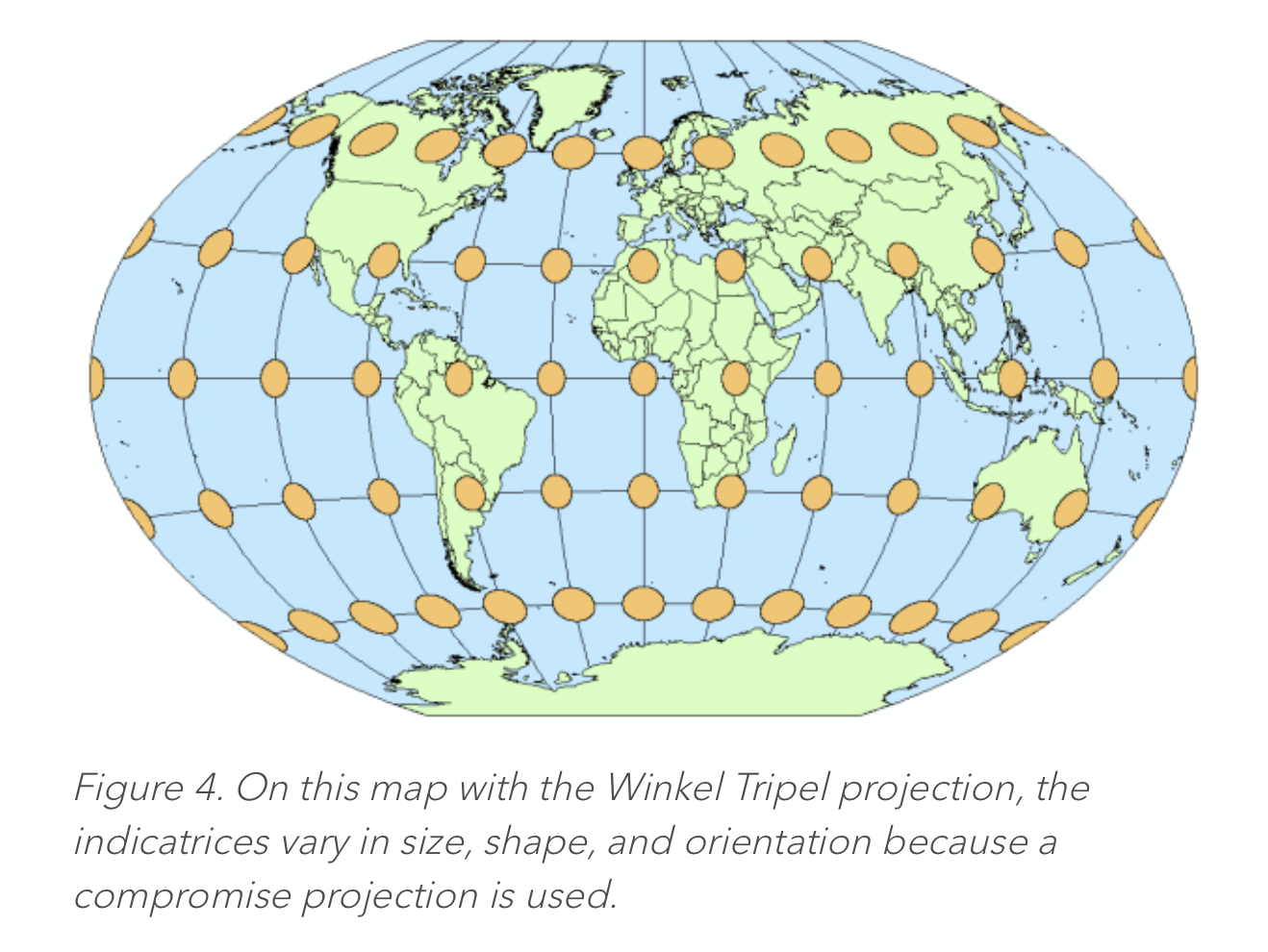
The orange ellipsoids above represent a “unit perimeter/sweep of the scale-factor vector” at each selected point. Tissot’s work proved that the shape of the unit perimeter was always an ellipse. I believe also that there is always a quadratic mapping between the ellipses at corresponding points in the two projections – another, but different “ellipse of influence” between the source and target grids. This is what the EWA algorithm uses – the unit perimeter of scale-factor as an “area of influence” from a source data point to the target projection. It computes the parameters for an ellipse in the target projection, based upon cell delta mapping/location values between the source and target grids.
For forwards projection, the source data is processed forwards to the target grid by calculating the target projected location and “ellipse of influence” for each source cell. At the end, each target cell has potentially multiple source cells that map to the target cell. The algorithm calculates a weighted average of all source cells that map to a given target cell. It calculates during the processing of source data points, the target points of reference, the weighted-values accumulated as the numerator, and the weights themselves summed as the denominator. After the source data is processed, the end results is the quotient of numerator to denominator values per target grid cell.
Overview and Discussion
- At its core, the EWA algorithm looks at the cell-to-cell delta in source to target cell mapping, both along and across track. These deltas are used to compute the parameters for a quadratic equation defining an “ellipse of influence” from a source cell to one or more target cells.
- The “ellipse of influence” is used both to compute which target cells are affected by a source cell – a bounding box to the ellipse of influence – and to compute a weighting factor for a weighted averaging of source cells per target cell. The weighting is defined in terms of the distance of the source cell center location to the target cell center (radius of the ellipse). Those source cells closer to the target cell are weighted more heavily than a simple linear cell-to-cell distance.
The “ellipse of influence” provides an important technique for calculating the area of influence, in the target grid. It is an efficient way of finding target cells when forward projecting the source data grid to the output grid. This permits a reasonably efficient “forward navigation” approach, versus more typical reverse projection algorithms.
Anti-aliasing Filter
- An important but not always evident aspect of the EWA algorithm is a further adjustment of the weighting factors to implement a gaussian filter to the projection processing. The gaussian filter is important to minimizing the possible aliasing and moiré effects when down-sampling a larger array of source data to a smaller set of target data.
The algorithm itself
What follows is a very cursory pseudo-code description of the algorithm, hopefully highlighting the important aspects, and not leaving out any significant details, while not overwhelming with detail.
For each point in swath (per row, per column)
Pre-Calculate ll2rc – lat/lon-to-row-column
(giving floating-point row/col in target space, not integer row/col)
For each row-set in swath (rows-per-swath)
Compute_ewa_parameters: (ellipse parameters per column)
For each column in swath
<compute ellipse parameters>
Use values in adjacent columns for horizontal delta of ellipse calculation
Use first row of row-set to last row of row-set, averaged over the number of rows
for the vertical delta of ellipse calculation.
Compute_ewa: (output values per target grid cell)
For each row in row-set
For each column in swath
<assign values for recurring factors >
<get ewa_parameters for row & column (ewa_parameters, ellipse)
<compute perimeter box for ellipse >
For each target row in perimeter box
For each target column in perimeter box
If target point within ellipse
Compute/Lookup weighting factor
Numerator_array(target_cell) += weighted-distance # grid_accums
Denomitnator_array(target_cell) += weights # grid_weights
Target_Values = Numerator_array / Denominator_array # output_grid
The original article shows the calculation of the perimeter-box for the ellipse as follows:
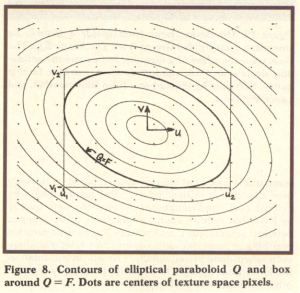
EWA Performance
- EWA should provide relatively good performance, relative to other reprojection techniques, though it remains computationally intensive to perform projection math on every point in the source grid.
- The PyResample implementation offers a built-in DASK application that should improve performance across multi-core/multi-processor systems, without requiring a huge memory footprint.
“Off-label” application of EWA
- Application to Geographically Gridded data, to regridding of data without reprojection, and to general reprojection of projection-gridded data
- The impact of the rows-per-swath parameter and options of rows-per-swath = 1 and rows-per-swath = 0 => all rows … .
- New modules to replace ll2rc – lldim2rc (Geographic Grids), rc2rc (Regridding, no projection math), xy2rc (Projected Grids, Double projection, Source-to-Target)
- Application to Geographically Gridded data
Application to Regridding - without reprojection
- Application to General Reprojection
Overview
Content Tools