Link to First Stage of Root Cause Analysis for CMR-9094
Document Overview
This performance analysis is based off running a 2021 production workload of search requests, examining only those requests with target format of UMM-JSON. The search requests were run using LogMiner (which parses a set of production logs and fires the same search requests it reads), with default pacing on full workload environment, against a modified version of CMR that had key functions wrapped with a 'time-execution' function that reports how long those take, along with extra logs to report those times. Logs captured the milliseconds (ms) that a request takes in 2 key areas:
- Section 1 -- comparing the database fetch stage vs entire data transform stage for each request (e.g. for each 'batch' of concepts returned)
- Section 2 -- the data transformation steps for each individual concept in a 'batch', which together with other computations compose the larger data transform stage from section 1.
Measures of central tendency
- It is standard advice to use
medianinstead ofavg(mean/average) when looking at data that is highly variable with many outliers that have extreme values, as we have here. - 95th percentiles and 75th percentiles are shown alongside median where appropriate in order to give a sense of distribution/variance without showing highest outliers in these skewed distributions
Change log
- 6/8/23 – Did not update section 'Comparing UMM-JSON transformation step(s) vs. total Transform Stage', but otherwise:
- Changed charts to use binning, which A) provides labels on x axes, and B) 'smooths out' the presence of outliers. Thus, mentions of outliers have been crossed out.
- Added date to all splunk queries (so they work as is without selecting date)
- Changed use of average and max to 95th percentile and 75th percentile, to lessen impact of outliers and because that's generally better for skewed distributions
- All descriptive text referencing the above, changed as appropriate
- Major updates to section 2: added more analysis to migrate umm step section (Table D replaced with Charts D1, D2), and corrected errors as well as added analysis to umm lib step section (updated Table E, added Charts F1, F2, F3 by metadata length, Tables G1, G2 by provider)
Section 1 -- Fetch stage vs Transform stage per request (batch)
These are search requests limited to target format UMM-JSON, and all are granule requests. (Collection requests hit a different function than the one tracked through this log.) Regardless, all splunk queries below contain where concept_type = ":granule" for the sake of queries being informative and re-usable.
Total number of events: 5,030
Chart A - time taken in Fetch stage vs Transform stage over Num. of Granules per search request
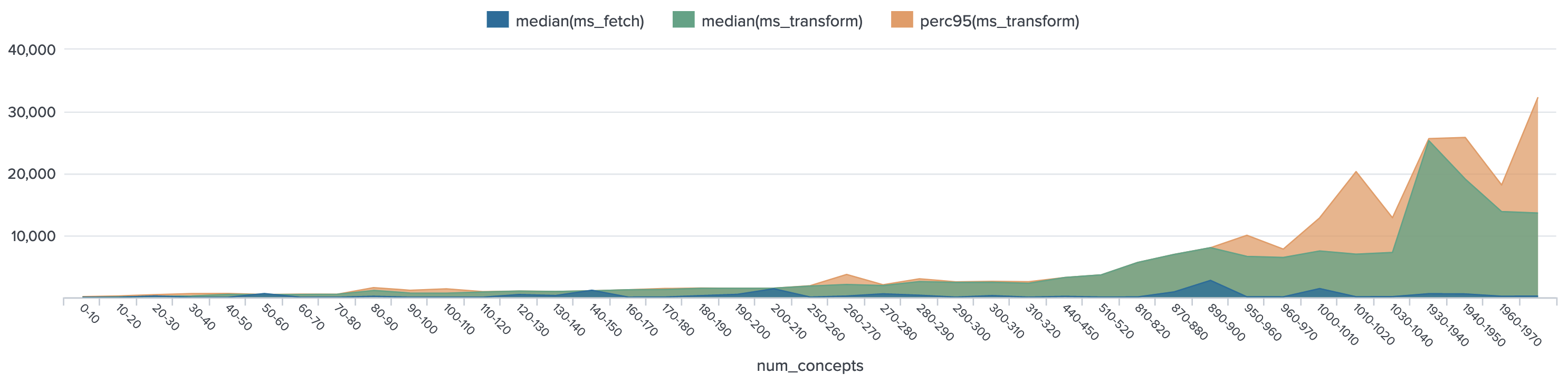
- Transform stage time overtakes Fetch stage as number of granules requested grows larger
- Note that Transform time 95th percentile (orange) significantly differs from the median (green) in the num_concepts range above 890 (implying greater variation and presence of outliers in this higher range)
Table B - Searches Grouped by Num. of Granules in Request

- Well over half of all UMM-JSON searches request less than 10 concepts, and another quarter request less than 50.
- As number of granules requested increases, Transform stage takes a longer proportion of total time, and its time grows faster than that of Fetch stage.
- The '500-899 concepts' category is very small (insignificant), which likely explains its funky values.
- The median_transform_to_fetch_ratio column is simply Transform time / Fetch time.
Table C - Time Per Granule Returned

- These are calculated times per concept, arrived at by simply dividing total stage time by number of granules in request. Recall that the median is the 50th percentile, shown alongside 75th and 95th percentiles for both Fetch and Transform stages.
- Fetch time per granule steadily decreases as number of granules requested increases. Transform time per granule is relatively more stable.
- When number of concepts is <50, there is much greater variation in time per granule for both stages, as indicated by 75th and 95th percentiles being quite different from the median.
Section 2 -- Per granule transformation step times
The entire transform stage for 1 request consists of: mapping over the batch of concepts, for each one selecting a transformation strategy, executing it, and attaching the result to the concept. For UMM-JSON, the relevant transformation strategies are "umm-lib" (granules only) and "migrate-umm" (for when both target format and original format are both UMM-JSON); their execution was timed.
Note: these logs capture steps that are used for both collections and granules, but for this report, all queries below have been limited to granules. Future section examining collections can be added if desired.
:migrate-umm transformation (umm to umm only)
This transformation has one step, the migration from the original UMM-JSON version to the desired version. The source_version field indicates the original version, and target_version indicates the version to convert to. Limited here to granules.
Total events (each one concept): 320,079
Chart D1 - Migration time vs metadata length

- Here we compare the median migration time as well as 75th and 95th percentiles over the length of the metadata of the granule being migrated.
- Median (blue) is barely visible in this graph because the median values are 1 ms across the board, except for the very final range of 10,750 char to 11,100 char where the medians become 2 ms.
- A slight positive correlation with metadata length is visible for the 75th percentiles of migration times, and a moderate one for the 95th percentile.
- Note that the 95th percentiles occur much further apart from the 75th percentiles, than the 75th percentiles to the medians (50th percentiles). This implies the presence of extreme outliers, and does occur for almost all metadata_length ranges, though moreso for the higher ranges.
Chart D2 - migration step time vs version distance
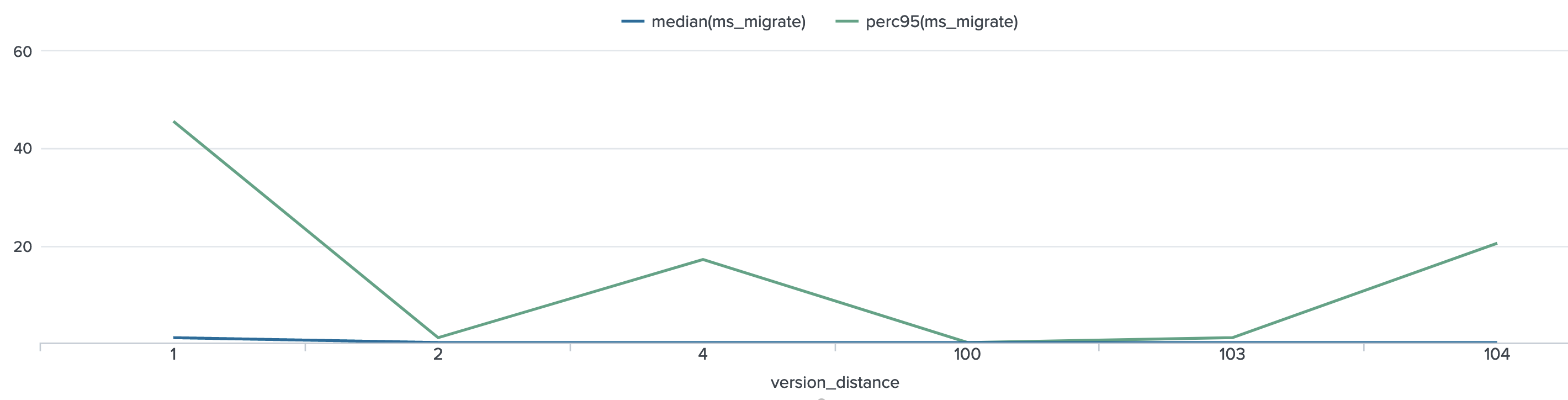
- This is to answer the question: does it take more time to convert between UMM-JSON versions that are further apart from each other? This is intuitive per the migrate-umm function's docstring: "Migrating across versions is just reducing over the discrete steps between each version."
- Version 'distance' is a calculated value representing how different the source version is from the target version. Versions are denoted according to semantic versioning format, e.g. "1.6.4" where 1 is the major version, 6 is the minor version, and 4 is the patch version. (with patch representing less difference than minor, and minor less than major) The splunk query first adjusts those values that are missing a patch version to have patch version 0 (e.g. assumed "1.5" is equivalent to "1.5.0"), then evaluates the
distancefield using the absolute differences between the major, minor, and patch components of the source and target versions. The differences are multiplied by specific factors(10,000 for major, 100 for minor, and 1 for patch) and summed together.
- For this sample, this produces just 4 discrete values for version_distance: 1, 2, 4, 100, 103, 104. That is due to a limited number of discrete values for source and target version.
- The chart shown here plots migrate time over version distance. The median migrate time stays stable over version_distance, while the 95th percentile does vary but does not show a correlation.
- (Author's note, can someone please check my work here? because this result is slightly surprising given the docstring description of how this function works)
- It is possible that metadata length is a stronger factor in migration time than version distance, and that version distance would produce a correlation if metadata length was factored out. Attempts to chart both together have so far not shown a straightforward correlation and are not pictured here because they are quite busy, but to help with that or check it out, replace the final
chartline of the query with the following:| bin metadata_length span=100 | chart median(ms_migrate) over version_distance by metadata_length
:umm-lib transformation (granules only)
This transformation has 2 steps: parsing the original metadata, and generating the UMM-JSON version. The 'mime_type' is the format of the original metadata.
Table E

- Total events (each one granule): 274,594
- Echo10 makes up the grand majority of concepts processed. ISO-SMAP is the only other source format represented and makes up only 0.002%.
- Echo10 shows great variability in the parse step, and the generate step shows extreme outliers (where the 75th percentile is still at 1 ms like the median, but the 95th is 39 ms).
Comparing UMM-JSON transformation step(s) vs. total Transform Stage (**Not updated since first draft about 5/25/23 run)
Does the slower subset from Table E represent an opportunity for optimization? Consider that Table C showed total transform-per-concept time to have strong centrality around 6 ms for all but the smallest requests (<10 concepts). The question is then, do the slower parse/generate events "belong to" those smaller search requests? (That would be problematic because the <10 search requests are the not the slow ones needing optimization.)
To answer that question, this section re-uses the same queries but limits them to only large search requests (>10 concepts).
For these use date 5/25/23 (added extra measurement long connection transformation step to size of parent request)
Chart E1 - total Transform Stage Time Per Concept over Num. of Concepts in request (for requests > 10 concepts)
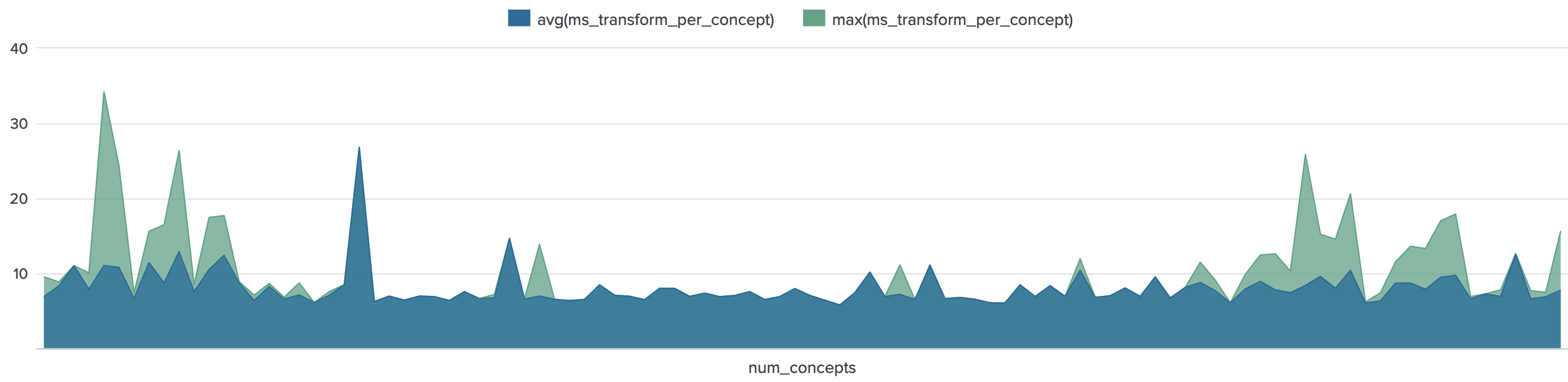
- The Transform Stage time per concept is remarkably steady for the middle request size range (between 50 - 275 concepts), staying around 6 ms for bother average and max.
- The average Transform time per concept never exceeds 10-12 ms (spike at 41 num_concepts is again a single outlier request)
- The ranges where the max (green) Transformation stage times exceed 10 ms are <25 num_concepts and >880 num_concepts. This suggests that it is possible that the those slower generate steps (>6 ms) "belong to" larger (>880 concepts) requests. (next chart explores that possibility)
Chart E2 - Umm-lib Strategy Transformation Steps Time over Num. of Concepts in parent request (for requests > 10 concepts)

- Outlier removal:
- Total number of events in umm-lib transformation strategy that belong to a parent request asking for at least 10 concepts: 317,625
- Number of those events whose total time (time for both parse and generate steps) is over 175 ms: 744 , which is 0.23%
- For that reason, events with ms_total over 175 ms were removed from this query as they constitute just a quarter of a percent, and have values so extreme (reaching into the 1000s of ms) that it severely warps a chart of maxes
- They can be re-added by removing the line
| where ms_total <= 175
- Similar to the last graph we compare average against max value, over number of concepts in request. (here, parent request) Again with the goal of determining whether there exist a significant subset of umm-json transformation step events with longer times that belong to larger (slower) requests.
- We also compare just the generate step time (average and max), against the total time (average and max), with the total being just generate + parse. Reason for honing in on the generate step, is that the parse step is not really specific to UMM-JSON, being a function that is used generally for parsing Echo10 XML, etc.
- We see that the 2 averages are much, much lower than the 2 maxes, even with the most extreme outliers removed. And the outlier removal was extremely conservative, removing only the top quarter of a percent (0.23%). This gives a sense of how wide the upper spread is/how extreme the skew.
- We do not see the averages vary with parent request size (staying around the 6 ms value seen in Table E). Maxes do seem to vary with request size somewhat, but it is difficult to make much of that without more aggressive outlier removal.
"How is this possible? That the max times per concept are 10-30 ms in the total Transformation Stage (request) view, but regularly around 100 ms in the individual concept transformation events view?"
- This is possibly due to the fact that the Transformation stage works on the whole 'batch' of concepts. The Transformation stage 'time per concept' is essentially an average, calculated by dividing by number of concepts. It is likely that while working on a batch, some concepts take much longer to transform than others depending on the metadata details.
- Moreover, if the Clojure engine is properly taking advantage of all available cores by parallelizing working on the batch, then the sum of the individual concept transformation steps could possibly exceed the time for the whole stage (because some would be happening at the same time).
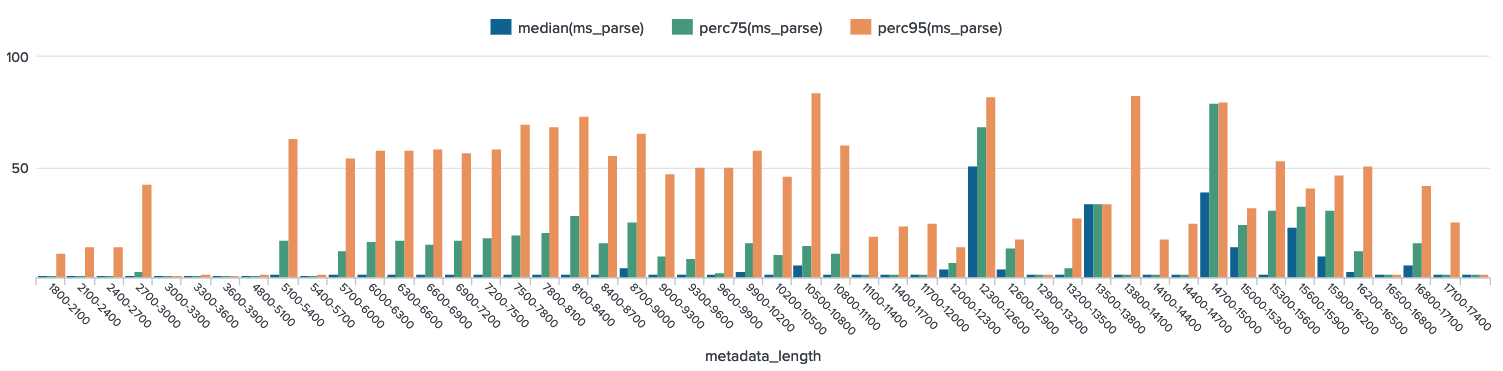
Charts F1, F2, F3 – Comparing umm-lib transformation step time with metadata length
- Here we check for a correlation between umm-lib transformation time and length of concept metadata in characters, and fail to observe an obvious correlation.
- Decrease in variability at the high ends occurs in bins that have too few events. (6 or even less)
- Three graphs are shown below, so that we may examine total time, generate step time, and parse step time separately. (With median, 75th, and 95th percentile shown for each) Recall that generate step + parse step = total time.
Chart F1 - Total Time

Chart F2 - Generate Time
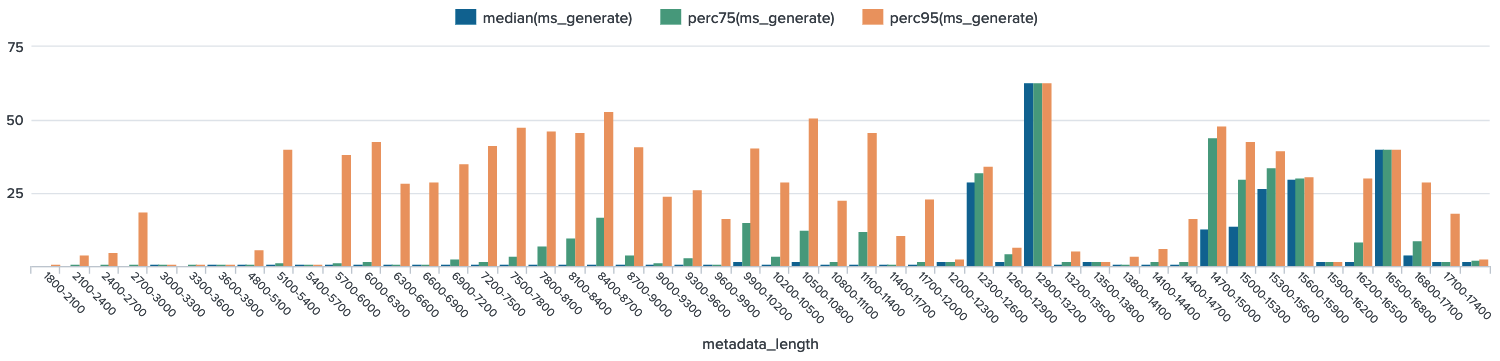
Chart F3 - Parse Time
Tables G1, G2 - umm-lib transformation by provider
Breaking down by provider might illuminate a relationship with metadata_length. For readability, both queries below exclude 3 providers (SEDAC, ORNL_CLOUD, GES_DISC) which were severely under-represented (10 or less events).
Table G1 - total time by provider
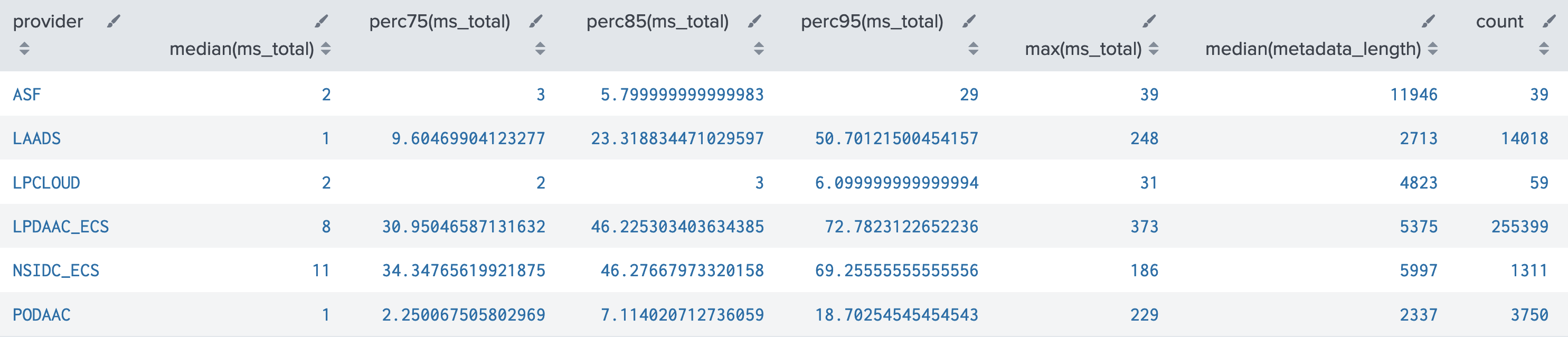
- This table shows each provider's median metadata_length (length of granule concept being transformed), alongside various percentiles, and max, of total time for the umm-lib step. The reason for so many percentiles alongside max is to check whether a provider's data might contain excessive outliers.
- LPDAAC_ECS and NSIDC_ECS are relatively slower than other providers:
- their medians (50th percentiles) are significantly higher
- their 95th percentile values are grossly higher, but even the 75th and 85th are already reaching around half the value of the 95th
- Other providers also show some slowing behavior, depending on how to define slow.
- Note that LPDAAC_ECS is the grand majority of events at 93% of the 274,576 total events
Table G2 – Metadata characters processed per millisecond, by provider

- The calculated fields named "chars per ms" are the result of taking the length of the granule being transformed, and dividing by the ms it takes to transform it, for both the parse and generate steps. The resulting units are "characters processed per ms", so a lower number means less characters processed per millisecond.
- Recall that the entire metadata is processed for both parse and generate steps, but for the generate step this is more of an estimate because the starting point is not the original string, but rather the result of the parse step.
- Generally, we would expect the median "chars per ms" to be very close to the median metadata_length, for the simple reason that most of the median transform step times were 1 ms. (E.g. 1500 chars/1 ms = 1500) This is exactly what's observed, with just 2 exceptions -- again LPDAAC_ECS and NSIDC_ECS, which both show much slower median chars per ms for the parse step. (but not generate step)
- 25th percentiles for chars per ms are given in order to examine the 'slowest' (less characters processed per ms) events. Which of these might be noteworthy depends on your definition of slow, some starting points:
- LPCLOUD doesn't vary, is incredibly steady across the board
- ASF exhibits 'slower' events only for parse, not generate
- Other remaining providers all show more slowing in parse than in generate, but they do show it in both. (how much is normal?)
Overview
Content Tools
4 Comments
Heather Grams
Action Items from the June 9, 2023 meeting:
Erich Reiter
implement metadata db as a library to avoid using https.
Karen Lucia Zimmermann
John Teague